Why Parallelism
Increasing data size
Limitations of single node architecture(bandwidth/memory limitation..)
Emerging affordable cluster architecture(Clusters of Linux nodes, Gigabit Ethernet connection)
Challenge
- Cheap nodes fail
Solution: Build fault-tolenrance into storage infrastructure(DFS, replicate) - Low bandwidth of commodity network
Solution: Bring computation close to the data - Programming distributed systems is hard
Solution: Data-parallel programming model
Users write “map” and “reduce” functions.
System handles work distribution and fault tolerance
1 GBps bandwidth in rack, 8 GBps out of rack - Other failure
Loss of single node, i.e. disk crash
Loss of entire rack, i.e. network failure
Hadoop Component
Distributed File System: files stored redundantly
Files are big
rarely updated
reads and append-only
- data node
file split into contiguous chunks(64 - 128MB)
each chunk replicated around 3 times and kept in different racks - master node
store meta data about where files are located, may be replicated
CLient library talks to master to find chunk servers, connects directly to chunk servers to access data - reliability and availability
data kept in chunks and chunks replicated on various machines(chunck server)
chunk servers also serve as compute servers
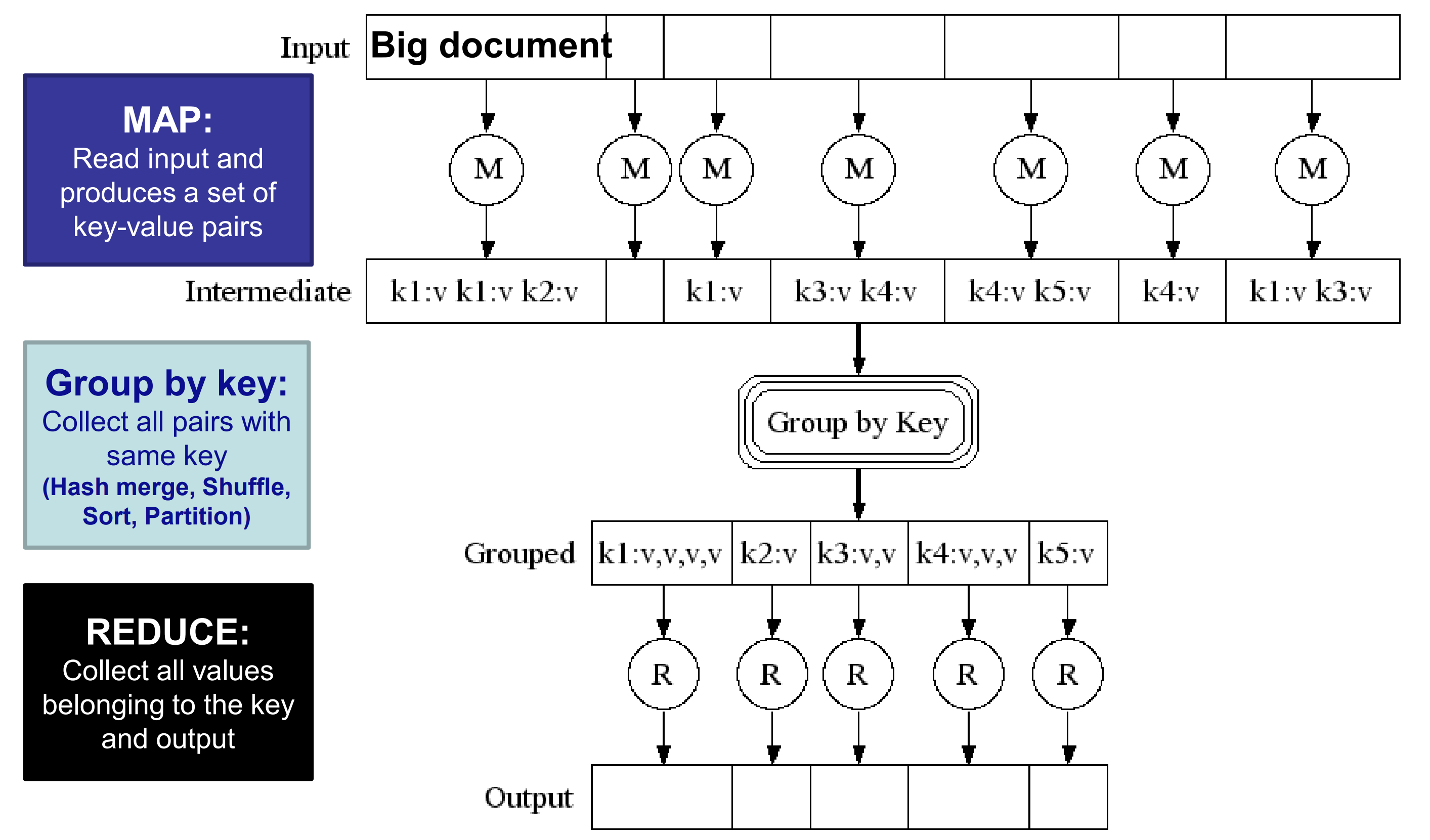
MapReduce Programming System: divide computations into tasks
MapReduce is a data-parallel programming model for clusters of commodity machines
- Sequentially read a lot of data
- Map: extract sth you care about (define by user)
- Group by key: sort and shuffle (done by system)
- Reduce: aggregate, summarize, filter or transform (define by user)
- write the result
MapReduce environment
takes care of
- partitioning input data
- scheduling program’s execution across a set of machines
- performing the Group by key step
- handling machine failures
- managing inter-machine communication
Grouping by key
- User defines number of Reduce tasks R
- System produces a bucket number from 0 to R-1
- Hash each key output by Map task, put key-value pair in one of R local files
- Master controller merge files from Map tasks destined for the same Reduce task as a sequence of pairs
MapReduce Diagram