Review on Transformers
self-attention
Idea: building a relationship between any 2 inputs (including itself)
RNN compute the hidden states sequentially, while in Attention they are computed in parallel.
q: query (to match others) $q^i = W^qa^i$
k: key (to be matched) $k^i = W^ka^i$
v: value (to be extracted) $v^i = W^va^i$
$\alpha_{i,j}$: the strength of the relationship between $x_i$ and $x_j$, We use each query $q$ to match each key $k$.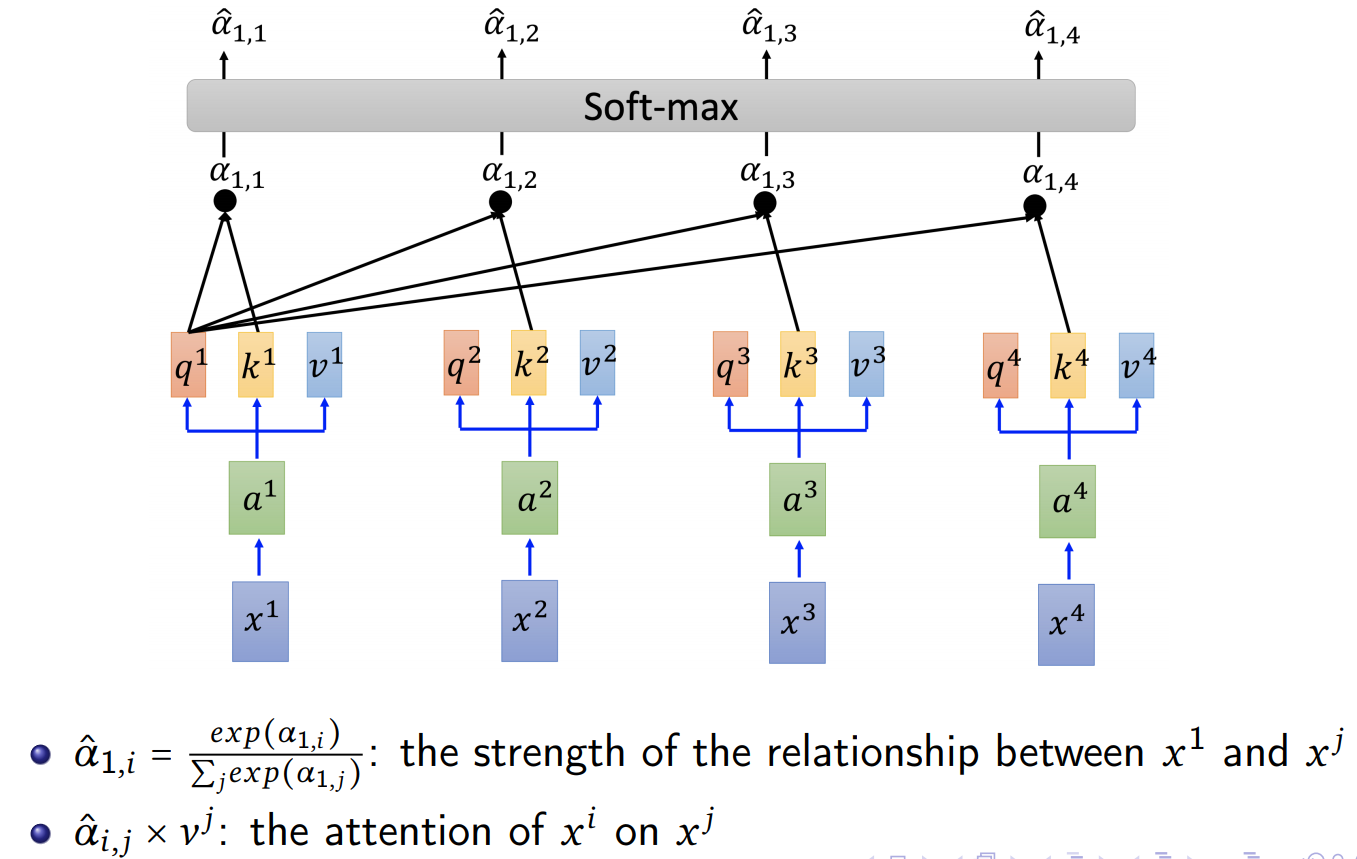
Hidden states $b^1$, $b^2$, $b^3$, $b^4$ can be computed in parallel: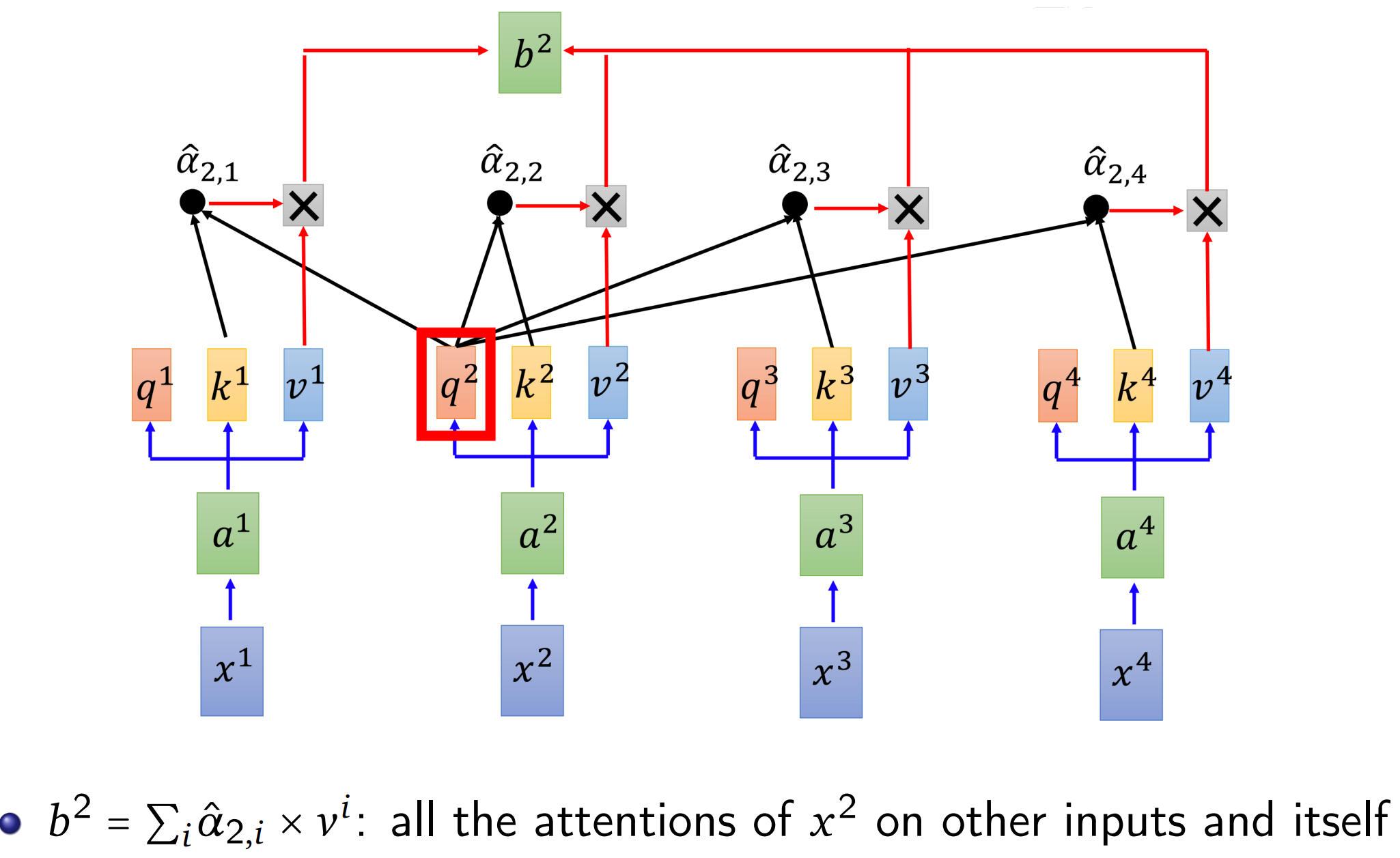
Multi-head self-attention
Example of 2 heads.
They can only communicate within the same head group.
We can merge the outputs the multiple heads into one output:
$b^{i,1},b^{i,2}…\Rightarrow b^i$.
Some heads focus on local information.
Some heads focus on global information.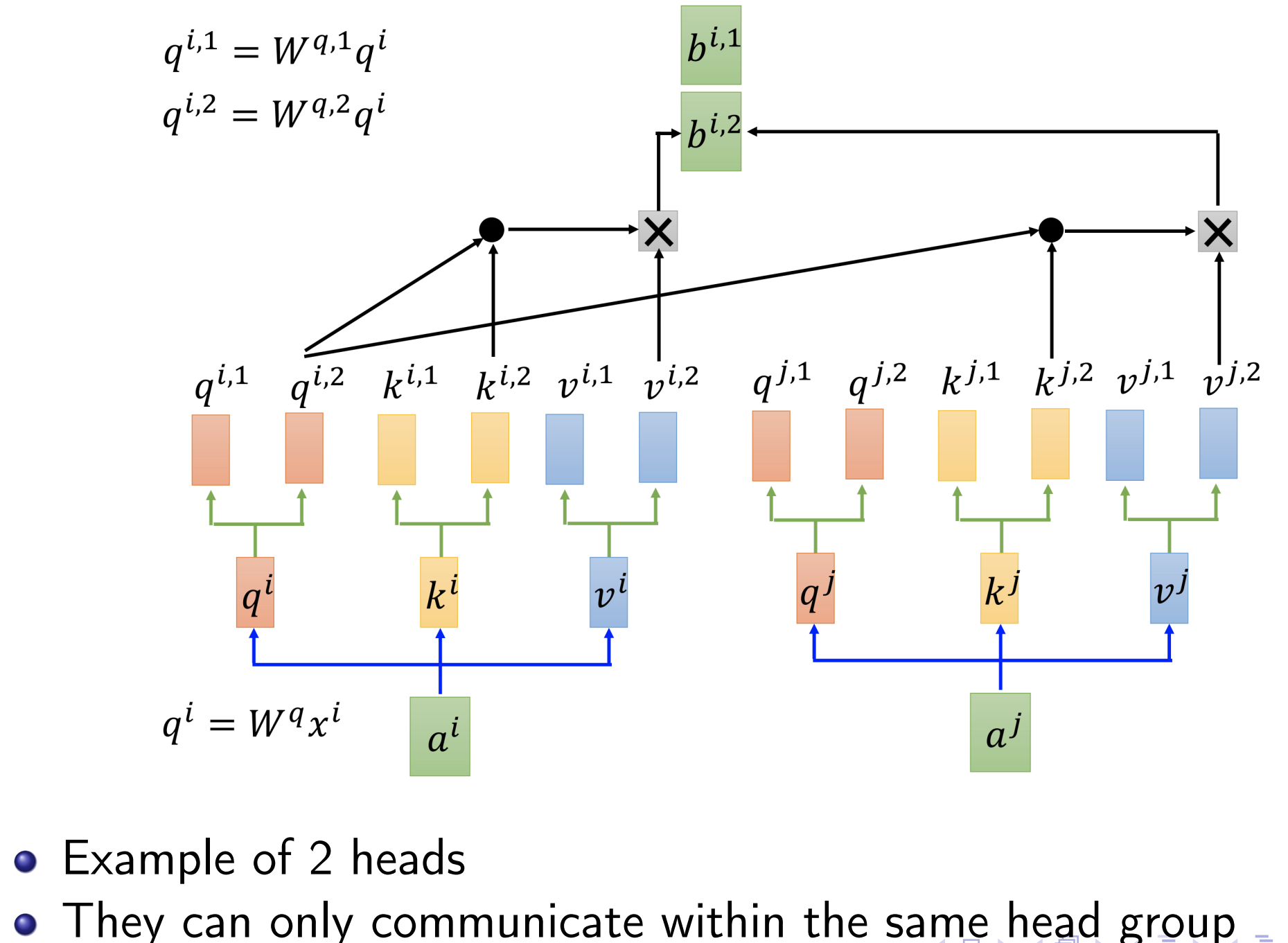
Transformers for Computer Vision
Unlike transformer in NLP tasks, in CV the information is not given sequentially so the inputs need to be cut into fixed-size patches, each patch with the its learnable position embedding(only has 1D info initially) construct the sequence input.
To perform classification, they use the standard approach of adding an extra learnable “classification token” to the sequence.
In BERT or ViT, the additional first token has nothing to do with a specific token or patch, can represent the whole sentence or image.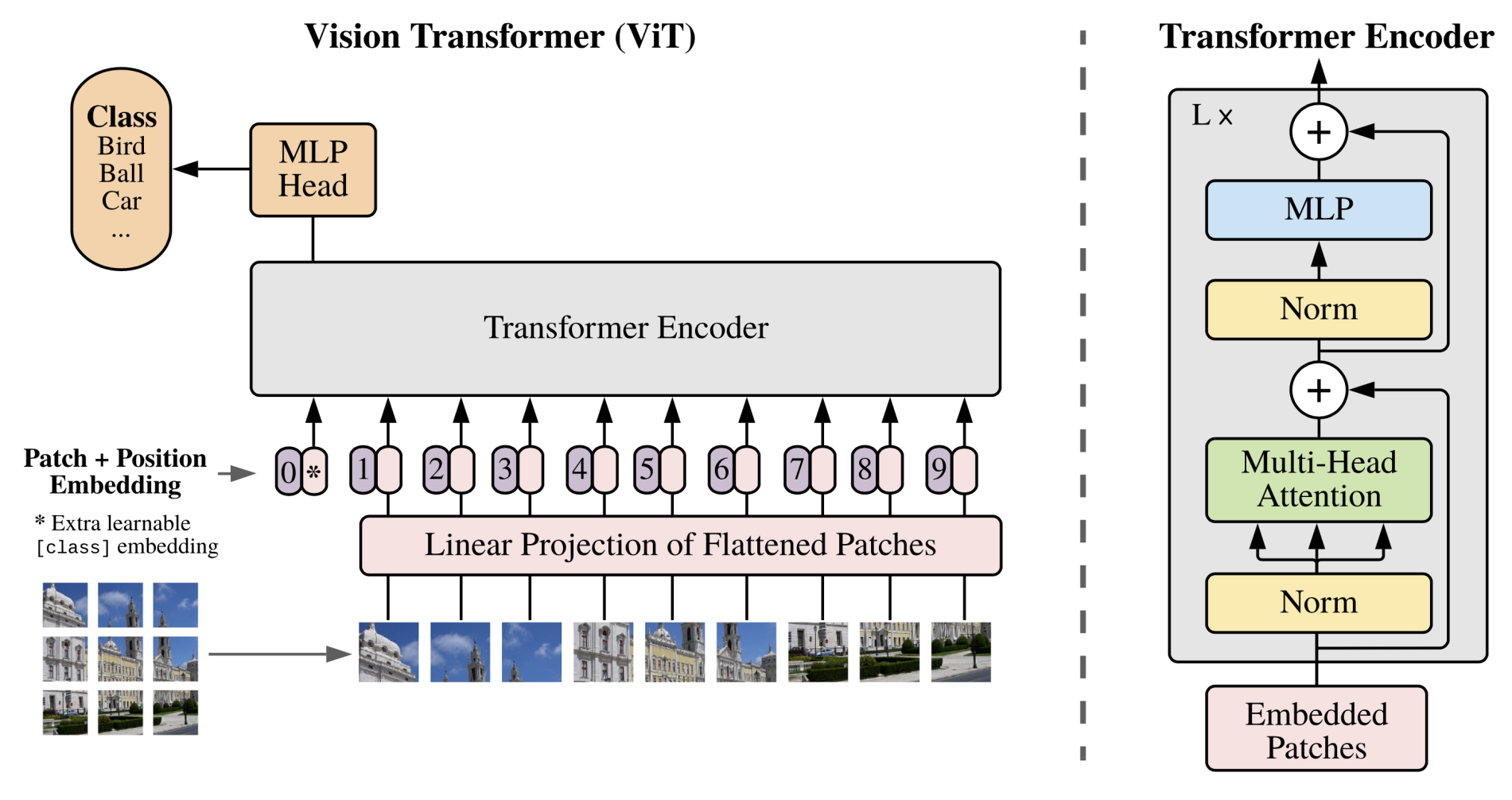
Hybrid: the position embedding vector is a CNN feature map.
Typically, we pre-train ViT on large datasets, and fine-tune to (smaller) downstream tasks. For this, we remove the pre-trained prediction head and attach a zero-initialized D × K feedforward layer(K is the number of downstream classes).
It is beneficial to fine-tune at higher resolution than pre-training.
Dataflow of a ViT encoder layer:
ALBERT: an efficient BERT
ALBERT significantly reduce the number of parameters in BERT.