Introduction
Simply increasing the number of parameters may have a negative impact on the performance.
Question is: how to scale the model effectively?
eg. Switch-Transformer(1.6T parameters)
The core framework is Mixture of Experts.
Conditional computation: word embedding(transfer a high-dimensional vector to a low-dimensional vector)
The goal is to increase model capacity without a proportional increase in conputational costs.
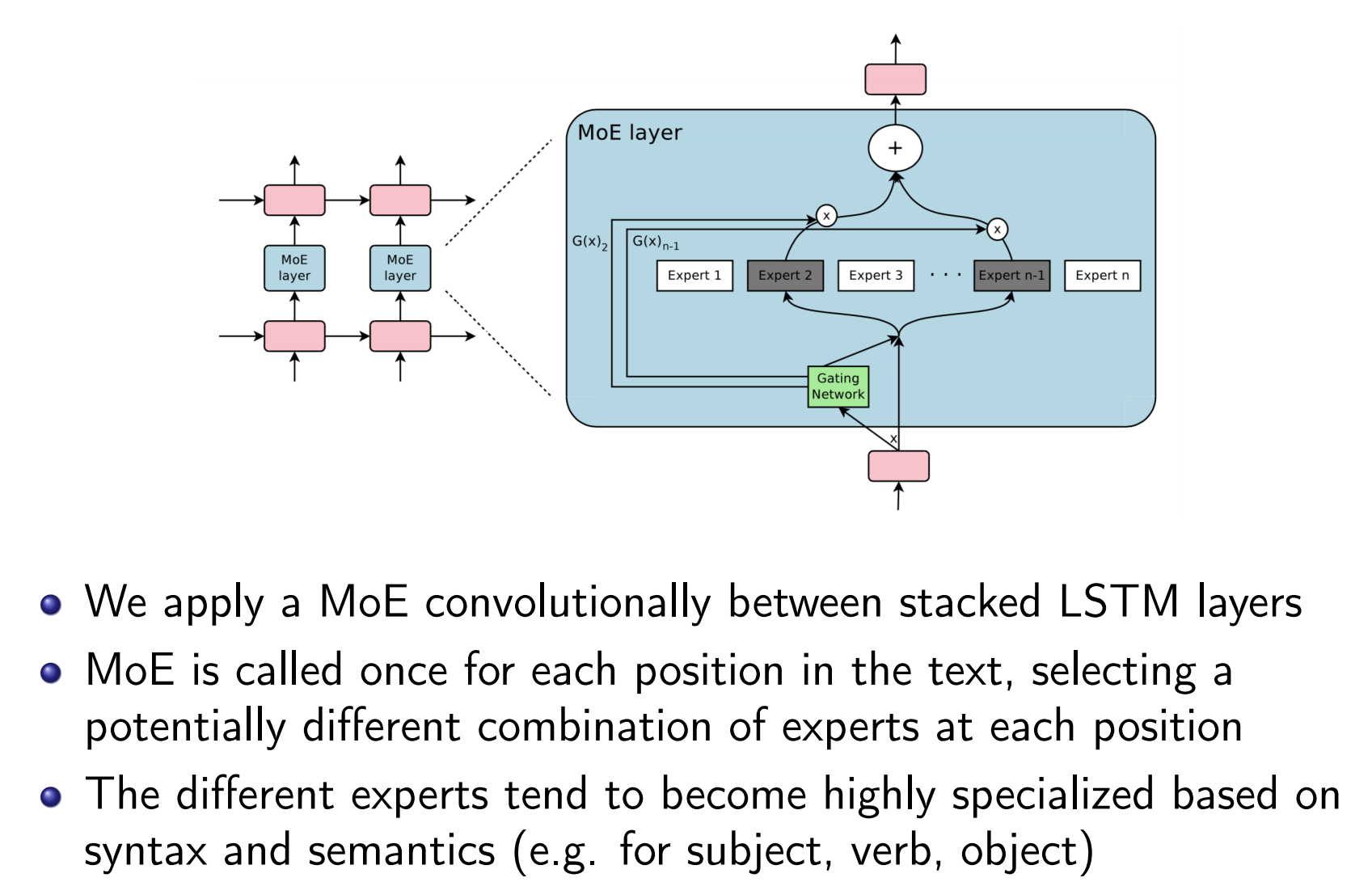
Sparsely-Gated MoE for LSTM
MoE layer has n expert networks $E_1,…,E_n$, each has its own parameters.
$G(x)$: output of the gating network, a sparse n-dimensional vector.
$E_i(x)$: output of the $i^{th}$ expert network.
Wherever $G(x)_i$ = 0, we don’t need to compute $E_i(x)$.
- Idea of conditional computation.
- We can have up to thousands of experts, but only need to evaluate a few of them for every example.
Gating networks:
- Softmax Gating: a simple choice of non-sparse function
- Noisy Top-K Gating: sparsity(save computation) and noise(helps with load balancing)

Load-Unbalanced Issue
Some experts have too many tasks, other experts are idle.
- The system’s speed will be limited by the slowest expert(the busiest expert), which is a very serious issue on distributed systems.
- The gating network tends to converge to a state where it always produces large weights for the same few experts.
- The load-imbalance is self-reinforcing: the favored experts are trained more rapidly and thus are selected even more by the gating network.

Why Transformers?
Many researchers are using transformer to replace LSTM.
Transformer: Encoder & Decoder