Introduction
Alpha Go: beat the best human Go player
AlphaFold: a solution to the protein folding
Reinforcement Learning is a feedback-based machine learning technique: an agent learns to behave in an environment by performing the actions and getting the feedback.
Sequential decision making + long-term goal(getting the maximum positive rewards)
No pre-program and only learns from its own experience
During the period of exploring the environment, agent’s state gets changed, and agent receives a reward or penalty after each action as a feedback. The goal of RL is to learn which actions lead to maximum point.
Terms used in RL
Agent
An entity that can perceive/explore the environment and act upon it.
based on hit and trail process;
may get a delayed reward;
get the maximum positive rewards.
Discount factor
Determines the importance of future rewards. A factor of 0 makes the agent “opportunistic” by only considering current rewards, while a factor approaching 1 will make it strive for a long-term high reward. If the discount factor meets or exceeds 1, Q-values may diverge.
Approaches to implement RL
Value-based
The optimal value function, which is the maximum value at a state under any policy.Policy-based
Find the optimal policy for the maximum future rewards without using the value function. (Deterministic VS Stochastic policy)Model-based
The agent explores a virtual model before exploring the environment.
4 key elements of RL
Policy: how agent behave at a given time.
It can be a look-up table or computation as a search process.
Deterministic: $a = \pi (s)$
Stochastic: $\pi (a|s) = P[A_t=a|S_t=s]$Reward Signal: at each state, environment sends a real-time reward signal.
Reward can change the policy to maximize the sum of rewards of actions.Value Function: how much reward an agent can expect in the current state.
Depends on the reward, the goal of estimating values is to achieve more rewards.Model of the environment: mimics the behavior of the environment for planning.
One can take actions by considering all future situations before actually experiencing them. (Model-based approach VS Model-free approach)
Types of Reinforcement learning
Positive Reinforcement
Increase the strength of behavior
Sustain the changes for a long time: an overload of states that can reduce the consequencesNegative Reinforcement
Avoid negative conditions
More effective
Provides reinforcement only to meet minimum behavior
How does Reinforcement Learning work?
First we have an agent and an environment.
We assign an intial value to each state and update it according to the rewards.
Bellman equation
It is used to calculate the values of a decision in dynamic programming at a certain point by including the values of previous states.
key elements used in bellman equation:
$a$: action performed by the agent
$s$: state occurred by performing the action
$R$: reward or feedback obtained at a state by performing an action
$\gamma$: a discount factor
$V(s)$: value at state s
$V(s’)$: value at the next state of s
We start the calculation from the block that is next to the target block.
Represent the agent state as the Markov Decision Process.
If the environment is completely observable, then its dynamic can be modeled as a Markov Process.
At each action, the environment responds and generates a new state.
Current state transition doesn’t depend on past actions/states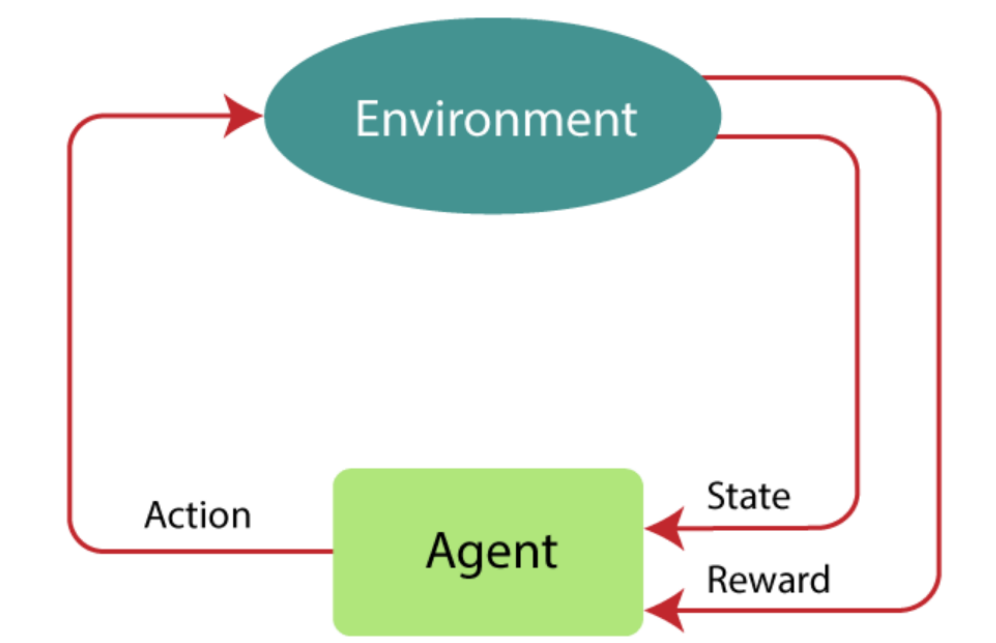
four elements contained in MDP:
$S$: a set of finite states
$A$: a set of finite actions
$R_a$: rewards received after transitioning from $S$ to $S’$ due to action a
$P_a$: probability of taking action a
In RL, we only consider finite MDP.
State $S$ and transition function $P$ can define the dynamics of the system.
The RL Algorithms
On-policy vs Off-policy
On-policy: learn policy $\pi$ from experience sampled from $\pi$, i.e, evaluate the policy that is used to generate data.
Off-policy: learn policy $\pi$ from experience sampled from $\mu$, i.e, improve a policy different from that used to generate data.
Temporal Difference Learning
learn how to predict a quantity that depends on future values of a given signal, comparing temporally successive predictions.
Q-Learning (off-policy)
It learns the value function $Q(S,a)$ which maps the state and action to rewards.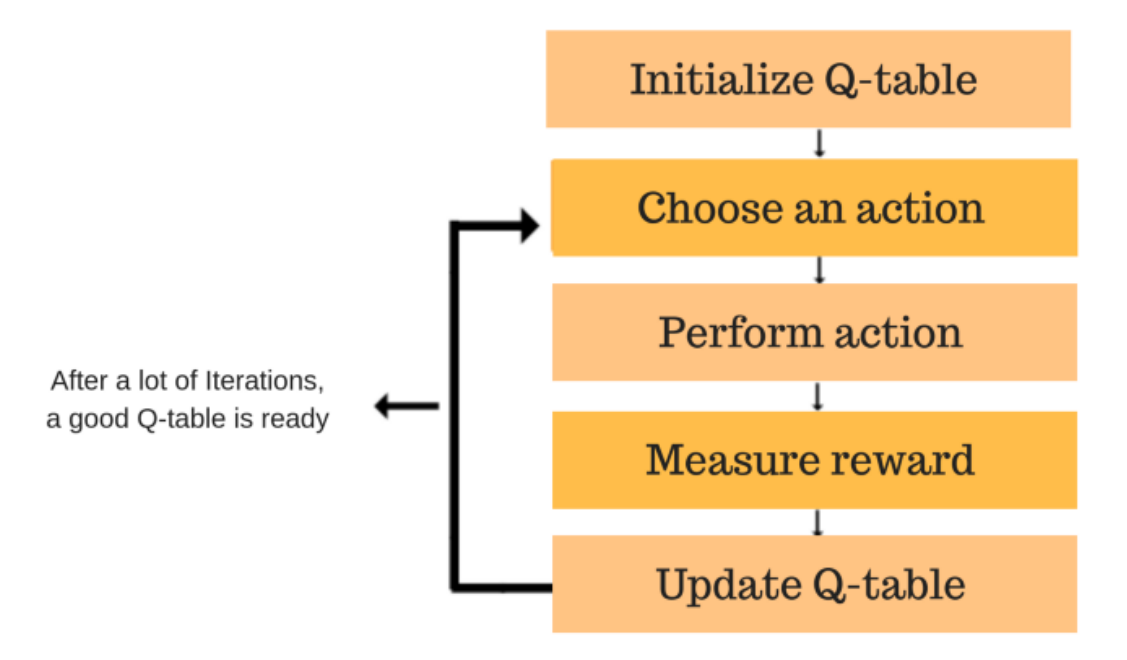
A model-free RL based on Bellman equation:
$P$ is the probability of turning to state $s’$ when taking action $a$ on state $s$.
Value of a state $s$ depends on the action that has the max Q-value on this state:
So we have:
After each action, the table is updated, and the Q-values are stored within the table.
State Action Reward State Action (SARSA, on-policy)
SARSA is an on-policy temporal difference learning method, selects the action for each state while learning using a specific policy.
The goal of SARSA is to calculate the $Q_{\pi}(s, a)$ for the selected current policy $\pi$ and all pairs of $(s, a)$. SARSA uses the quintuple $Q(s, a, r,s’,a’)$:
$s$ and $a$: original state and action,
$r$: reward observed while following the states,
$s’$ and $a’$: new state, action pair.
Deep Q Neural Network (off-policy)
In a complex environment where exploring all possible states and actions costs too much, we can use neural network to replace the Q table and make approximation of sequential actions.