Paper: https://arxiv.org/abs/1902.04885
Introduction
As the technology grows rapidly, more and more attentions are paid to Artificial Intelligence, one of the most famous examples is Alpha Go. It used 30000 games to train the model and finally defeated the top human Go players. The current rapid development of AI largely depends on the availability of Big Data.
The real-world situations, however are less encouraging. We have the following troubles such as limited amount of data, data without high quality, and it may cost a lot to exchange data, we should meet the requirements of laws and go through administrative procedures. Sometimes, considering the industry competition and privacy security, it is impossible to get more data at all. In this case, most of time we are confronted with a big issue: how can we fuse enough high-quality data for training a machine learning model legally with a low cost.
In general, all the problems above can be concluded as two parts: data island and data security, which lead to federated learning framework to achieve model training regardless of these troubles.
Federated Learning
Federated Learning is a machine learning setting where the goal is to train a high-quality centralized model while training data remains distributed over a large number of clients each with unreliable and relatively slow network connections.
Here are some privacy protect methods for FL:
The First is Secure Multi-party Computation. SMC models naturally involve multiple parties, each party knows nothing except its input and output. But this setting requires complex computation protocols and be may hard to achieve effectively.
As for Differential privacy, The basic idea is to add noise to the data, or use other methods to obscure certain sensitive information until the individual cannot be distinguished. We can see this method leads to a trade-off between accuracy and privacy.
Also, we can use Homomorphic Encryption to guarantee privacy through parameter exchange under the encryption mechanism, while the data and the model itself are not transmitted, so there’s risks in raw data leakage.
Federated Learning can be divided to three categories:
Horizontal federated learning
The first kind of FL is Horizontal federated learning.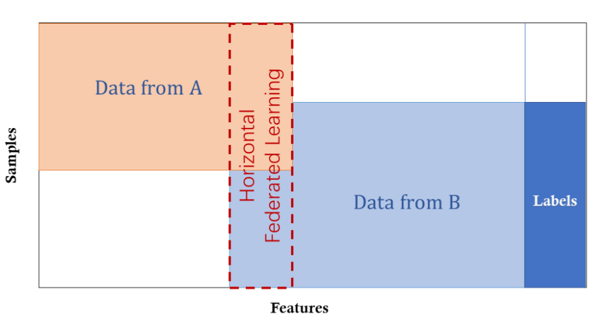
Each row of the matrix represents a sample, and each column represents a feature. In HFL, datasets share the same feature space but different in samples. For example, people in different cities leads to different samples, while the banks in different cities have similar functions, i.e., similar features. Therefore, we can train a ML model using decentralized data.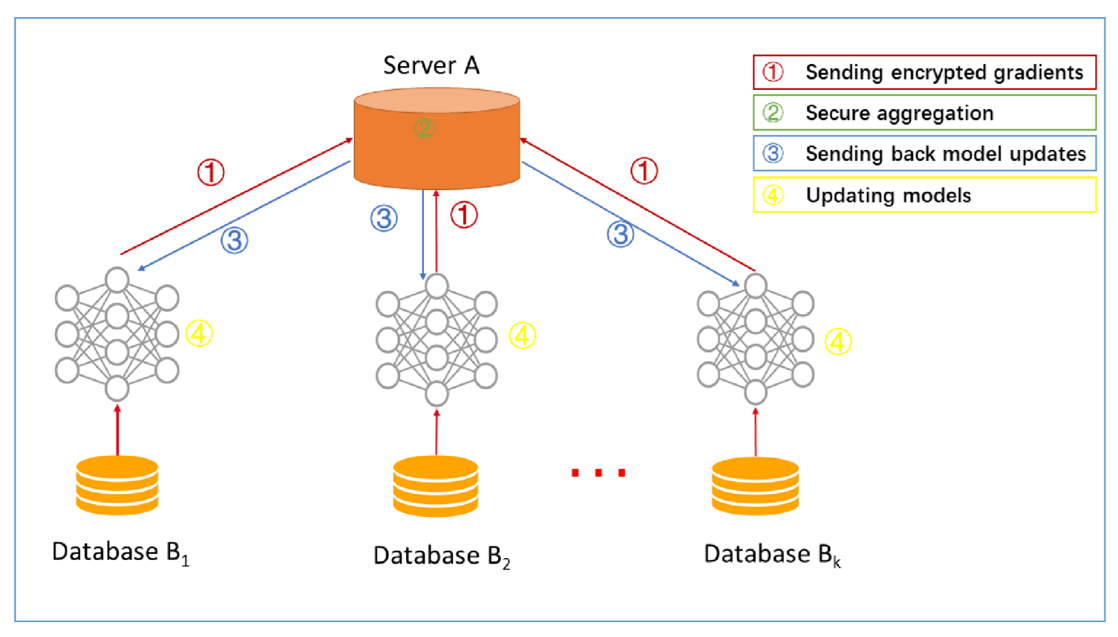
This figure shows a typical architecture of server/client horizontal federated learning system. In the first step, the clients locally train the model, mask the gradients using differential privacy or other encryption techniques and send their encrypted gradients to the server. Then the server aggregates the gradients and updates the model. Next, the server sends the model parameters back to clients and clients update their local model. This process will loop until every party gets a satisfying model.
In the whole process, there’re are no information leakage between any parties.
And this architecture is independent from specific ML algorithms that the clients choose to train and all participants will share the final model parameters.Vertical Federated Learning
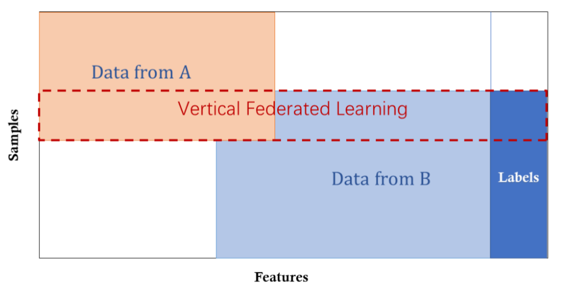
We can see from the figure that in this framework, datasets have different features but similar samples. For example, the bank and shopping mall in the same city, they have the same target clients while their services are quite different. In this case we can jointly train a model for product purchase based on user and product information.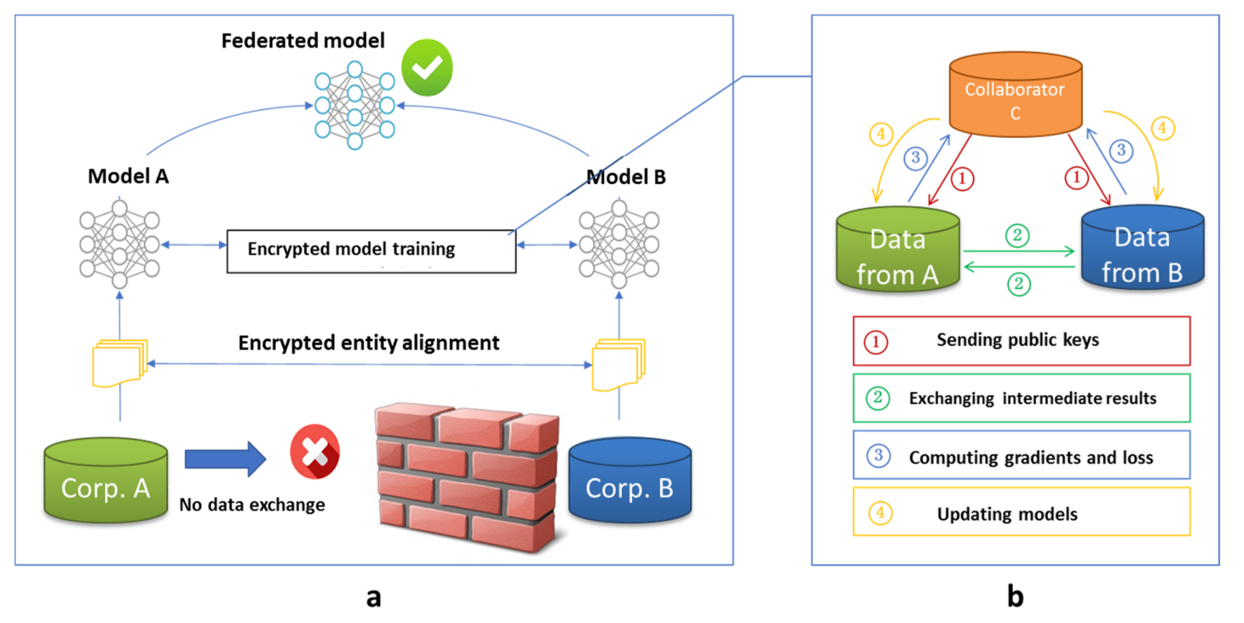
As for the architecture of vertical federated learning, suppose A has training data while B has training data and labels. We want to model how the data in A and data in B jointly influence the value of label. Since A and B cannot exchange data directly, we need a third party, C to help with the model training.
To start with, we need to confirm the common users between A and B without exposing users that do not overlap. This process is called entity alignment.
Then we’ll begin model training. Firstly, the collaborator C send public key to A and B. Then A and B exchange encrypted intermediate result. After exchanging, A and B compute encrypted gradient and loss and send to C. C decrypts and send gradient and loss back to A and B, the clients updates their model locally.Federated Transfer Learning
Federated Transfer Learning applies to datasets differ in both sample space and feature space. For instance, the datasets from bank in China and hospital in Singapore. Finding similarities (invariants) is the core of transfer learning. So we learn a representation between the two feature space using the overlapped sample sets and apply this model to obtain predictions for samples.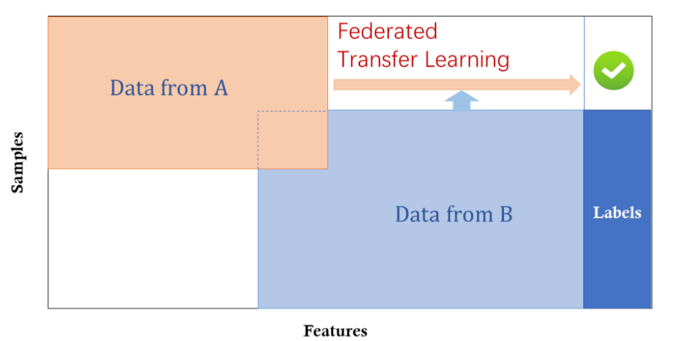
In the scenario of TFL, datasets have only a little set of overlapping samples. It does not change the architecture of vertical federated learning, but different in detail which tries to find the common representation among the parties.
Incentive mechanism means after the model is built, the local model’s performance depends on how much this party contribute to the whole federated system. Combining the incentive mechanism may improve the entire architecture, encouraging more organizations to participant and provide more data.
Related work
Federated learning can be considered as privacy-preserving decentralized collaborative machine learning and most of the privacy protection techniques using in privacy-preserving machine learning can be applied in Federated learning
Horizontal federated learning is similar to Distributed Machine Learning to some extent. This figure shows an example of distributed machine learning using distributed storage of training data. In distributed machine learning, the parameter server allocates data on distributed working nodes and compute model parameters in a scheduled way. However in Federated learning, each working node which is the data holder, can independently decide when and how to join federated learning. What’s more, federated learning focus on the privacy protection during parameter transferring while distributed machine learning makes no achievements in this security issue.
Edge computing is also closely connected to federated learning. Federated learning can provide protocols of implementation details that helps to guarantee data security as well as the improvement in accuracy of global model. In this case federated learning can work as an operation system for edge computing.
Federated Database Systems are systems that integrate multiple database units and manage the integrated system as a whole. Compare to distributed data system, working nodes in federated database system store heterogenous data. So federated database has similar type and storage of data compared to federated learning. But as a database system, federated database system mainly focuses on the basic operations of data such as inserting, deleting and searching while the goal of federated learning is to jointly train a model that works well in each independent unit. Meanwhile federated database system does not have a privacy protection mechanism.
Applications
The first common application of federated learning is smart retail. Smart retail aims at providing personal recommendation and services based on user’s preference and purchasing power. However, these features may be stored in different places: purchasing power can be analyzed from bank saving, user’s preference can be indicated from social media and information of product is recorded in the e-shops.
In this case we are facing the problem that these three kinds of organizations cannot exchange data directly so the data are scattered and cannot be aggregated.
The other problem is data Heterogeneity.
Heterogeneous data are any data with high variability of data types and formats. They are possibly ambiguous and low quality due to missing values, high data redundancy, and untruthfulness. It is difficult to integrate heterogeneous data to meet the business information demands.
The solution is Federated learning and Transfer learning. We can use federated learning to break the data island and use transfer learning to handle the Heterogeneous data, in this way we can train a model using data in various parties to achieve personal recommendation and break through the limitations of traditional artificial intelligence techniques Therefore, federated learning provides a cross-enterprise, cross-data, and cross-domain ecosphere of big data and artificial intelligence.
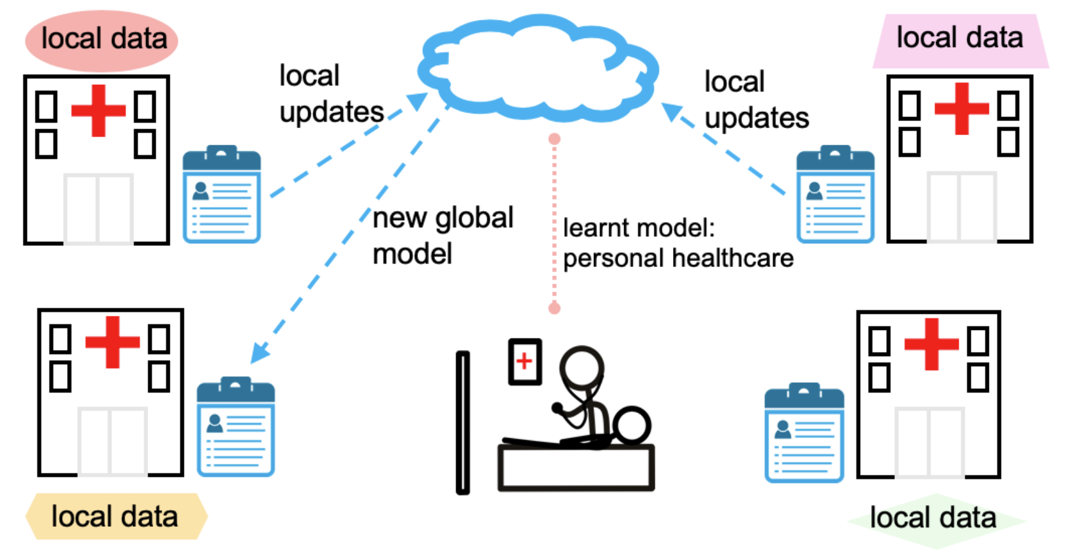
Smart Healthcare is obviously a direct application of horizontal federated learning. Different hospitals treat different patients, but are doing research for the treating of the same diseases. Due to the limitation of people treated in one single hospital, each hospital may not get enough data for a certain disease. Medical information is definitely sensitive information that involves patient privacy. Therefore, hospitals cannot exchange data directly. In this case we can use federated learning to jointly make use of data in different hospitals to train a global model that works well in each single hospital and protect patients’ privacy at the same time.
Conclusion
It is expected that in the near future, federated learning would break the barriers between industries and establish a community where data and knowledge could be shared together with safety, and the benefits would be fairly distributed according to the contribution of each participant.
Here are some of my insights.
One of the challenges for federated learning is the Non-IID data as introduced in the section of distributed machine learning. So the main problem is that when we are using SGD in local models, we’ll face the problem of weight divergence, as we can see in the figure, the global model does not work well on each local datasets. So I think we can use adaptive optimizer as it can learn from the history gradient, which means it can make use of local data distribution when computing local gradients and can solve the problem of weight divergence to some extent.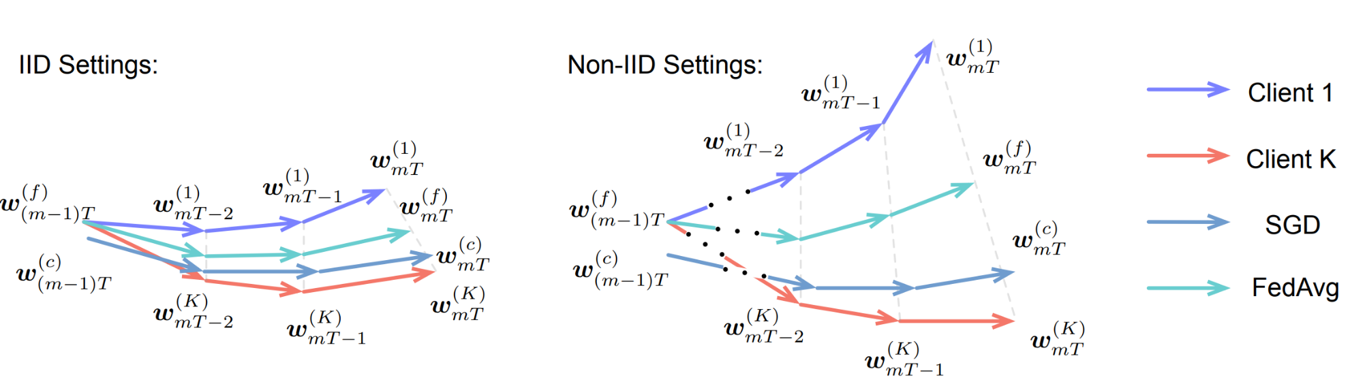
Yue Zhao,Meng Li,Liang zhen Lai,Naveen Suda,Damon Civin,and Vikas Chandra.2018. Federated Learning with Non-IID Data
And the other thing I notice is that all the framework above assume no delay for each nodes’ model transferring to the server, i.e, the server has to collect all gradients before updating global model. This lead to the fact that server may wait for too much time for collecting all gradients in one single round. So, I think the federated model can work asynchronously. Every time the server receives a model from A, the server updates the global model and immediately sends the new model back to A. Therefore, there’re less time waste in one round and more efficiency.