Historical Notes
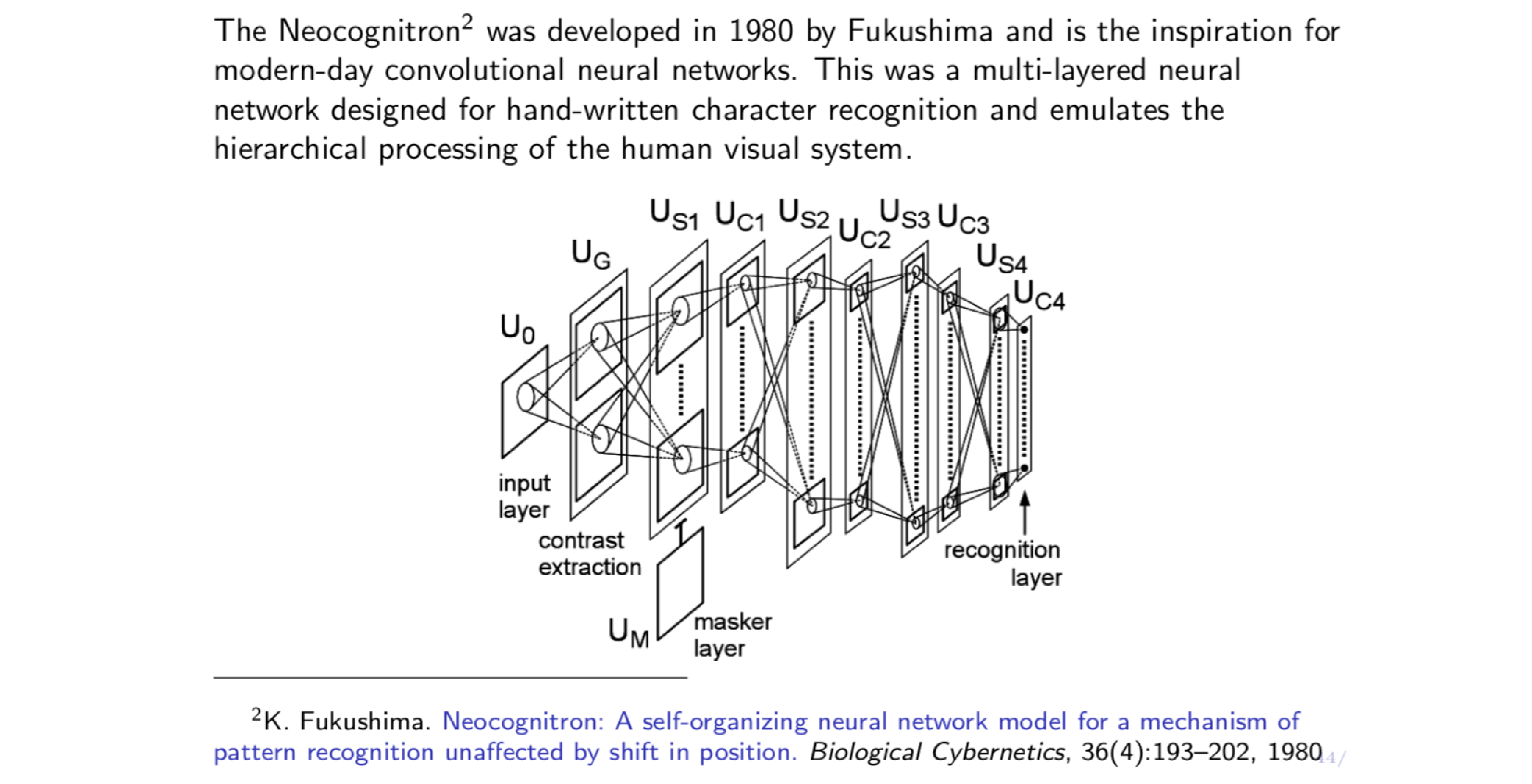
Fukushima’s Neocognitron
- Hierarchical feature extraction
- Local connectivity field
- Hand crafted weight (before BP was developed)
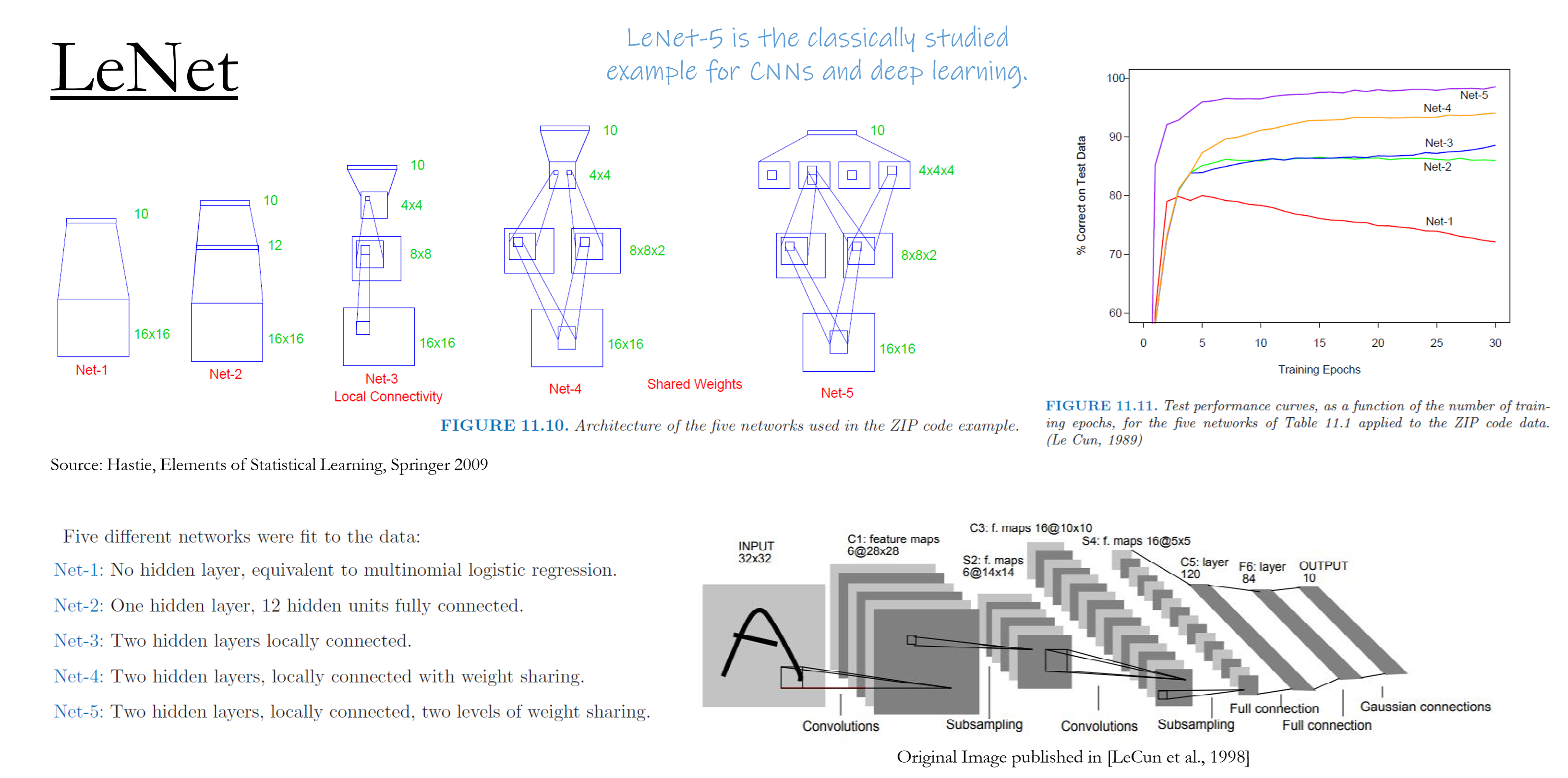
LeNet
- Convolution
- Subsampling = pooling
Modern CNNs
General Architecture and Design Guide
ConvBlock(module): convolution, activation, batch normalization, pooling
Classification: Linear + Activation + Softmax
Regression: Linear
Accuracy: large representation capacity $\to$ overfitting
AlexNet 2012
GPUs instead of CPUs
Emsemble modelling
ReLU: reduce the chance of gradient vanishing
Dropout: avoid overfitting
Image Augmentation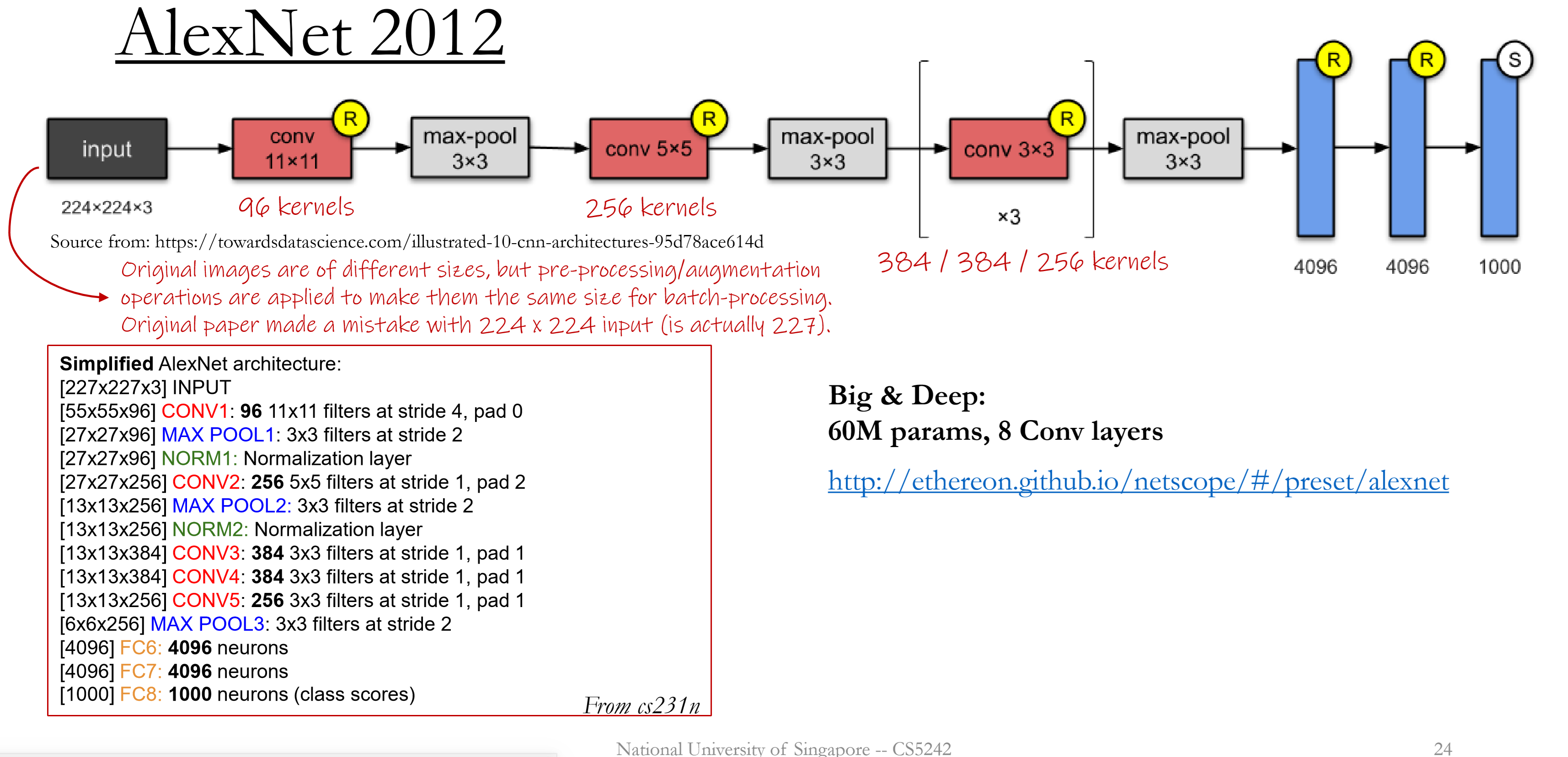
Dropout
Training
Randomly set some neurons to 0 with probability p
Different layers may have different dropout rateInference
Do Nothing ! Stay deterministic during prediction
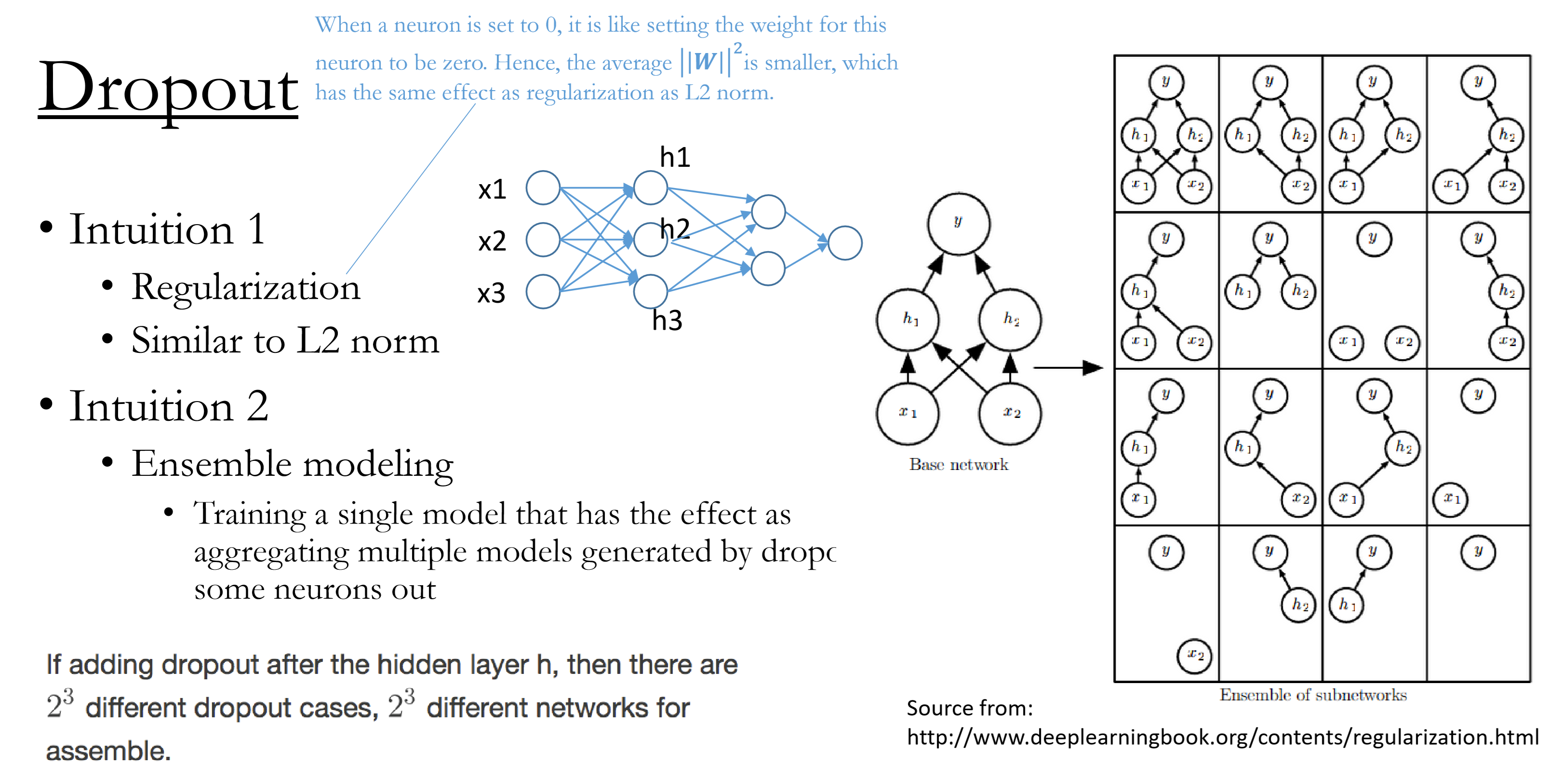
Image Augmentation
Increase the training data to cover more types of (test) data.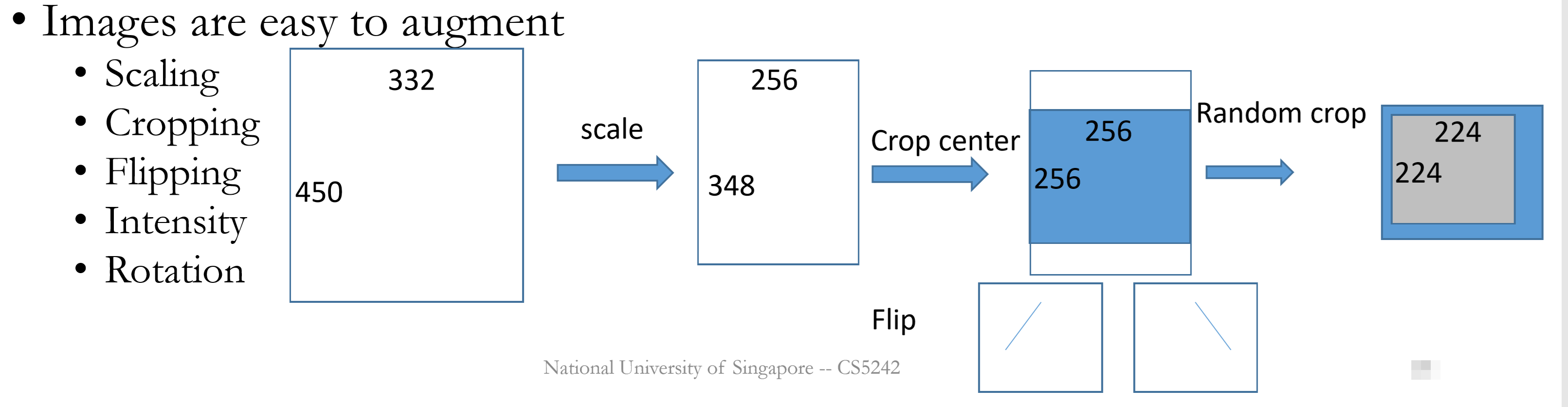
Training
Random augmentation operationsTest
No random operations, otherwise model may generate different predictions for the same input run twice.
Make predictions by aggregating the results from all augmented images.
VGG
Unified kernel size
Computational cost: 2 3x3 kernels < 1 5x5 Kernel
Deeper structure(16, 19 convolution layers)
More parameters(138M).
More non-linear tranformation; Larger capacity.
Consecutive convolution.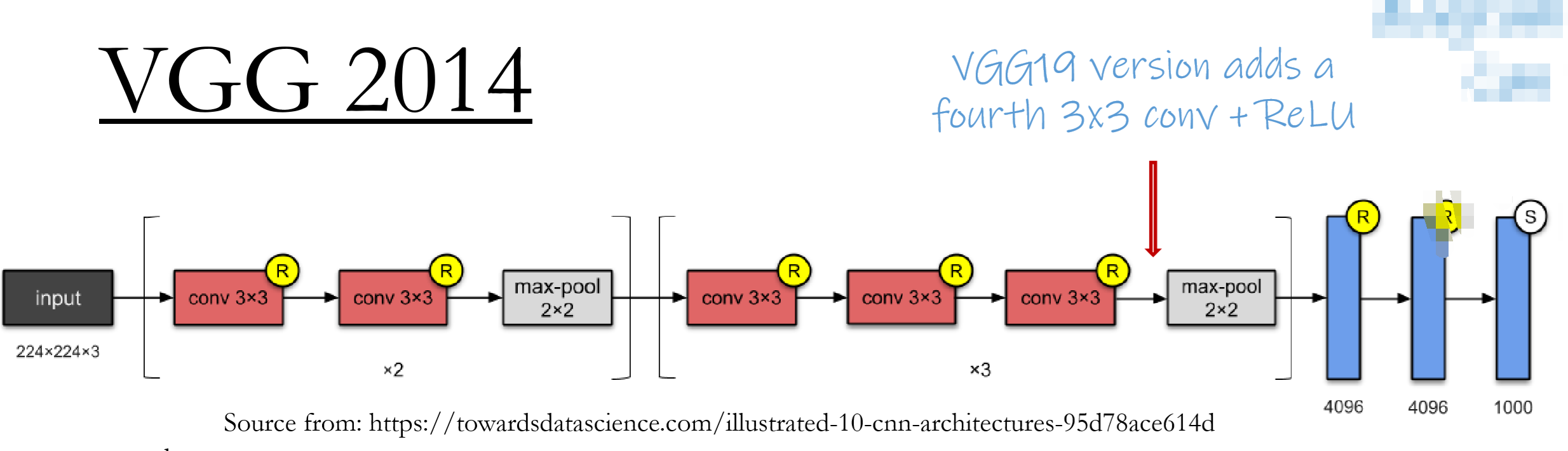
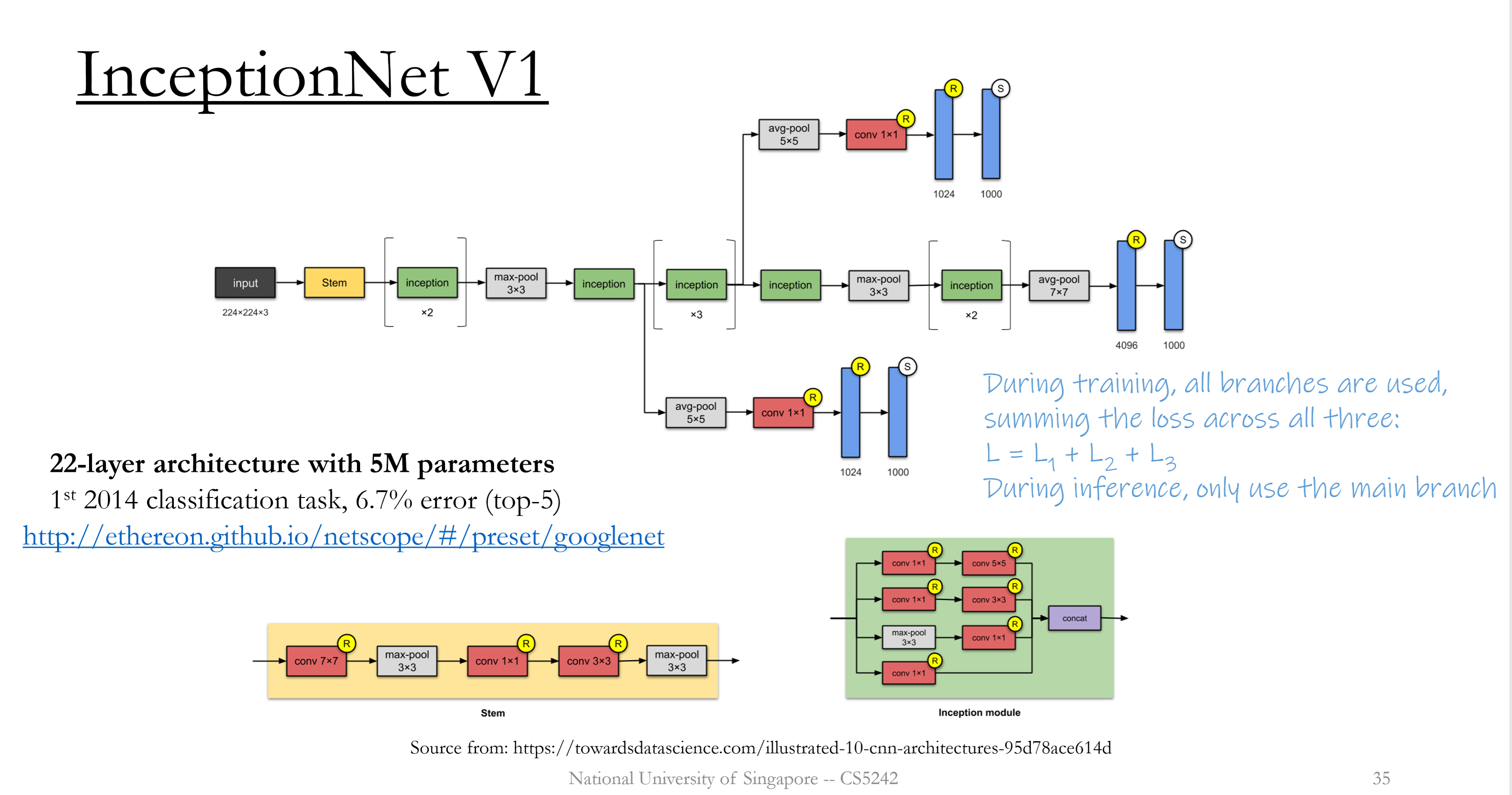
Inception V1
Inception Block : $1\times 1$ convolution (reduce channel number); ensemble multiple paths with different kernel sizes.
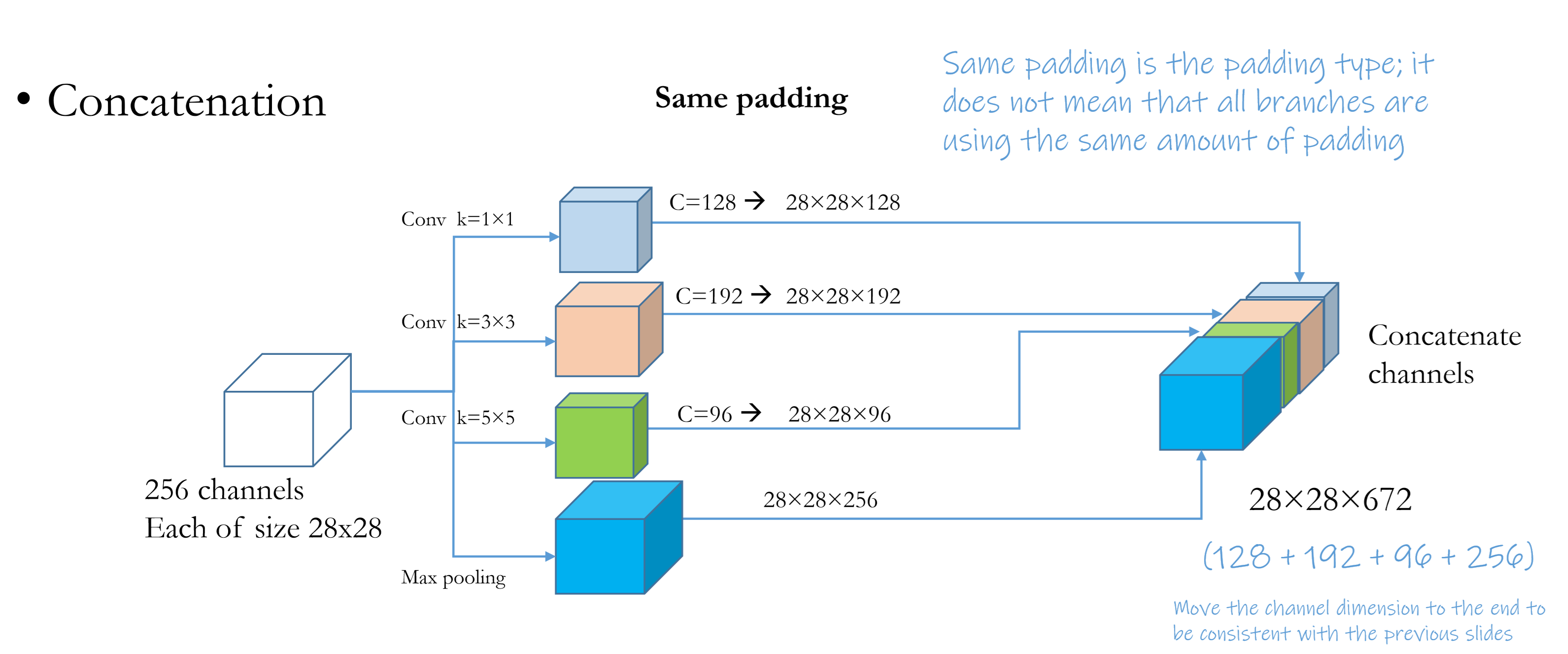
Achieve fusion of feature maps in a single level using concatenation of output from kernels with various size.
- Average pooling: reduce model size & time complexity.